Why Trust Cannot Be Built in a Single Layer: Introducing the Identifier Trust Layers Framework
Most businesses protect their sign-up flows with one tool. A WAF blocks known bad actors at the network edge. A CAPTCHA challenge filters robotic behavior. An email verifier checks that mailboxes exist. A KYC provider confirms identity before onboarding completes.
Each of these tools is genuinely useful. Each solves a real problem. And each covers only one specific moment in a user's journey.
The gaps between them are where fraud finds leverage, either slipping through undetected or creating costly noise across fragmented layers.
What a Trust Layer Actually Means
A trust layer is a distinct point in the user lifecycle where specific types of signals become available for evaluation.
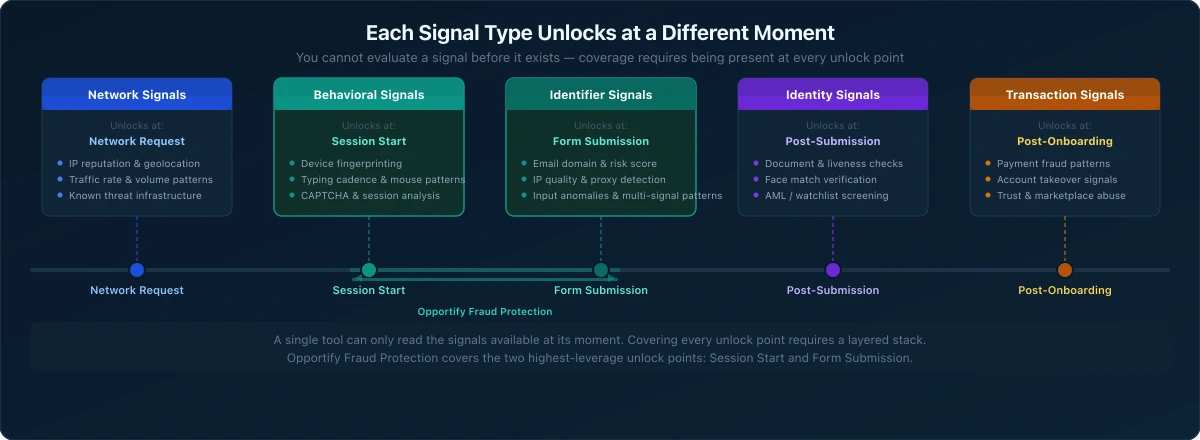
This is a meaningful distinction. Different signals become readable at different moments:
- Network signals are available before any user interaction occurs: IP reputation, traffic patterns, known threat infrastructure.
- Behavioral signals become available during the user's session: how they interact with the page, how the form is filled, how their device behaves.
- Identifier signals become available at the moment of submission: the email address provided, the IP used to submit, the phone number entered, the quality and consistency of the data.
- Identity signals become available post-submission, when a verification workflow is triggered: documents, face match, liveness detection.
- Transaction signals become available after onboarding, when the verified user starts taking actions in the product.
Each type of signal is only actionable at the right moment. Trying to evaluate behavioral signals before a session starts is impossible. Trying to catch a fake email domain with a WAF rule is the wrong tool for the job.
Building a strong fraud prevention stack means having coverage at every moment where risk can be evaluated, not just the moments that are easiest to instrument.
The Single-Layer Trap
A WAF cannot evaluate the quality of an email address submitted through a form it already allowed through. A CAPTCHA cannot assess whether the person who solved it is using a stolen identity. An email verifier cannot detect whether the verified mailbox belongs to a real human or a synthetic persona. KYC cannot undo the damage from a fake lead that contaminated your CRM two weeks before the verification step was triggered.
These are not weaknesses in individual tools. They are structural gaps in how fraud stacks are assembled. Each tool does exactly what it was designed to do, at the moment it was designed to operate. The problem is that typically, no single layer can see what another layer sees.
Businesses that rely on one or two layers often discover fraud in the wrong place: downstream, after resources have been consumed, after pipelines have been contaminated, or after the verification budget has been spent on users who never should have reached that stage.
The answer is not to replace any of these layers. The answer is to understand how they map to the user lifecycle, and where the critical gaps are, so you can apply the right tools at the right moment and avoid the downstream cost of fragmented, siloed fraud signals.
Introducing the Identifier Trust Layers Framework
Opportify's Identifier Trust Layers framework maps where trust is evaluated across the full user lifecycle, from the first network request through post-onboarding activity. It defines five distinct layers, each with its own signal type, threat profile, and moment of evaluation.
The framework is not an industry standard. It is how Opportify structures thinking about fraud prevention coverage, gap analysis, and product positioning.
Here is how the five layers map to the user lifecycle, and when each type of signal first becomes readable:
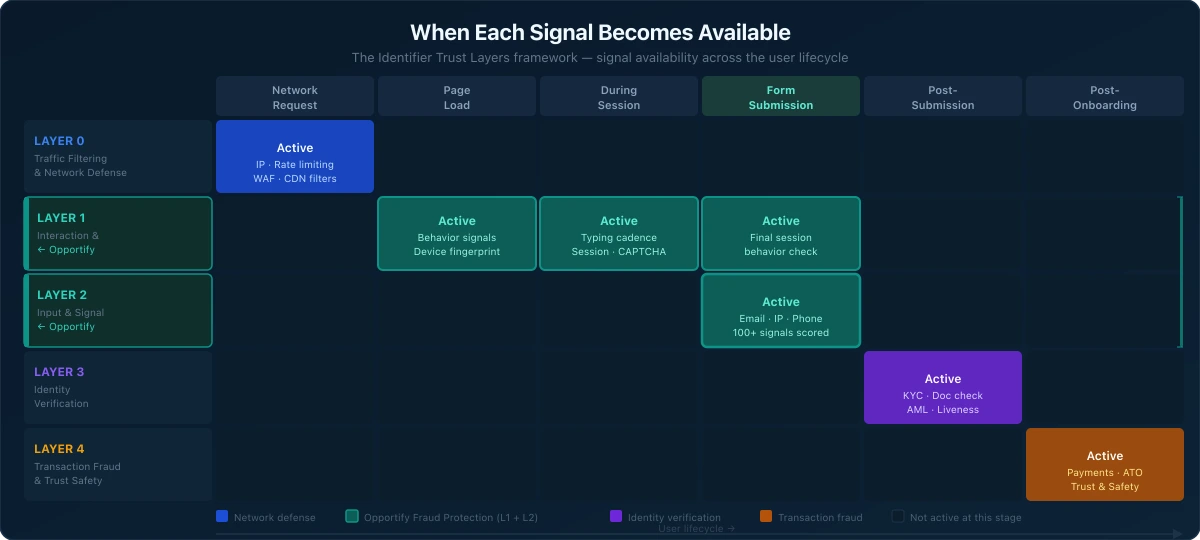
| Layer | Name | When | What It Evaluates | Key Threats Caught |
|---|---|---|---|---|
| Layer 0 | Traffic Filtering and Network Defense | Before any user interaction | WAF rules, rate limiting, IP blocklisting, CDN-level threat filtering | Known bad IPs, volumetric attacks, Tor exit nodes, high-rate flooding |
| Layer 1 | Interaction and Session Intelligence | During the user's session | Behavioral signals, device fingerprinting, session analysis, CAPTCHA | Robotic behavior, device fingerprint reuse, automated patterns, human-assisted abuse |
| Layer 2 | Input and Signal Intelligence | At submission | Email, phone, IP, and input signal analysis, risk scoring across submitted identifiers | Fake emails, high-risk IPs, input quality anomalies, multi-signal fraud patterns |
| Layer 3 | Identity Verification | Post-submission | Document checks, liveness detection, face match, AML/PEP/sanctions screening | False identity claims, synthetic identities (partially), watchlist matches |
| Layer 4 | Transaction Fraud and Trust and Safety | Post-onboarding | Payment fraud, account takeover, chargeback abuse, marketplace manipulation | Fraudulent transactions, ATO patterns, abuse of trust-based systems |
Each layer also has a blind spot, which is as important as what it catches.
Layer 0: Traffic Filtering and Network Defense
This is the network perimeter. It operates before any user interaction occurs, which means it requires no user input to function. WAF rules, CDN-level blocklists, rate limiters, and IP reputation databases all operate here.
Layer 0 is effective at stopping high-volume, low-sophistication attacks: known malicious IPs, volumetric floods, Tor exit node traffic, and infrastructure used in previous attack campaigns.
Its blind spot is anything that looks like legitimate traffic. A residential proxy rotated from a clean IP, a human completing a form, or an attacker using a shared cloud address that is not yet on a blocklist: all of these pass through Layer 0 without friction.
Layer 1: Interaction and Session Intelligence
Once a user lands on a page, behavioral signals become available. Device fingerprinting, scroll patterns, typing cadence, mouse movement, session timing: all of these are readable before the form is submitted.
CAPTCHA of all types (classic checkbox-based, invisible behavioral, and Cloudflare Turnstile) also operates at this layer. These are challenge-response mechanisms that require user interaction, which is why they sit at Layer 1 rather than Layer 0.
Layer 1 is effective at catching robotic behavior, device fingerprint reuse across sessions, and some patterns of human-assisted abuse.
Opportify's Fraud Protection covers this layer as part of its two-layer pre-onboarding coverage.
Its blind spot is the identity behind the session. A clean device, a human interaction pattern, and a solved CAPTCHA tell you nothing about whether the email address about to be submitted is real or synthetic.
Layer 2: Input and Signal Intelligence
This is the submission moment. When a user provides their identifiers (email, phone, IP, and form content), this data becomes available for analysis.
Layer 2 evaluates the quality and risk profile of those identifiers: disposable or temporary email domains, high-risk IP addresses, input anomalies, multi-signal fraud patterns, and the consistency of the data provided across signals.
This is where Opportify operates. More on that below.
Its blind spot is identity verification. Knowing that an email address is real, not disposable, and from a low-risk domain does not confirm that the person using it is who they claim to be.
Layer 3: Identity Verification
After submission, when a business decides to verify a user, identity verification tools become relevant. Document checks, liveness detection, face match, and AML/PEP/sanctions screening operate at this layer.
Layer 3 is designed to catch false identity claims, synthetic personas with real-looking documents, and matches against watchlists.
Its blind spot is the fraud risk that existed before the verification step. KYC does not retroactively clean data that entered the pipeline at Layer 1 or Layer 2. By the time KYC runs, the cost of processing a fraudulent submission has already been incurred.
Layer 4: Transaction Fraud and Trust and Safety
Once a user is onboarded and active in your product, transaction-level signals become available. Payment fraud, account takeover attempts, chargeback patterns, and marketplace manipulation are all detectable here.
Layer 4 tools are powerful, but they inherit the quality of everything above them. If fraudulent accounts entered through gaps at earlier layers, those accounts are now inside the product and generating activity that transaction fraud tools must evaluate.
Its blind spot is the root cause: which layer the fraudulent account slipped through, and why.
Where Opportify Operates
Opportify's Fraud Protection operates at Layers 1 and 2: Interaction and Session Intelligence combined with Input and Signal Intelligence.
This combination covers the pre-onboarding trust gap. It is the stage after traffic filtering and before identity verification, where most fake identities, fake leads, and form abuse enter pipelines undetected.
By combining behavioral session signals with identifier-level risk scoring across 100+ signals per submission, Fraud Protection surfaces risk at the moment a user submits a form. The product delivers a normalized risk score (200–1000) and explainable signals, giving businesses the context to act before a submission reaches a CRM, pipeline, or KYC workflow.
Fraud Protection outputs are risk signals. The decision on how to act on those signals remains with the business.
This two-layer coverage is also the most cost-effective point in the funnel to evaluate fraud. Every submission that passes Layers 1 and 2 without being flagged increases the likelihood that it will consume KYC processing budget, cloud resources, or manual review time at Layer 3 and beyond. Catching risk earlier reduces downstream cost at every layer.
For a deeper look at why this gap exists and what fills it, see WAF and CAPTCHA Alone Cannot Protect Modern Funnels.
How Each Layer Depends on the Ones Before It
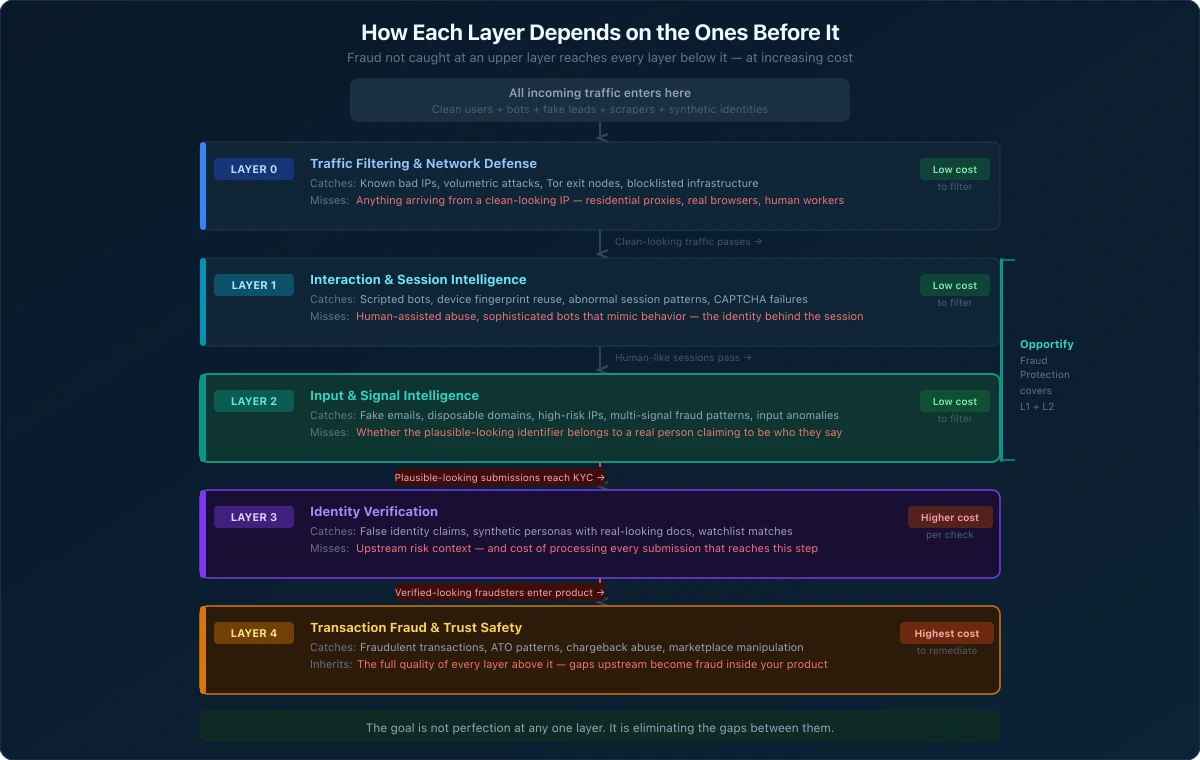
The Identifier Trust Layers are not independent checkpoints. They are a connected system where the effectiveness of each layer depends on the strength of the layers above it.
A fraudster who slips through Layer 0 reaches Layer 1. A fraudster who evades Layer 1's behavioral detection reaches Layer 2 with a clean session. A fraudster who passes Layer 2 without being flagged reaches Layer 3 with a legitimate-looking submission. A fraudster who clears Layer 3 is now a verified user at Layer 4, and every transaction they make must be evaluated without the benefit of the upstream context that should have filtered them out.
This cascade has a practical consequence: weak or missing layers increase the burden on every layer below them. A business with no Layer 1 or Layer 2 coverage sends every submission, clean and fraudulent, directly to KYC. KYC tools are expensive, slow relative to earlier layers, and designed for identity verification, not for filtering bulk fake submissions.
Similarly, transaction fraud tools at Layer 4 inherit the quality of the user population that reached them. If fraudulent accounts accumulated during onboarding, Layer 4 must detect and remediate them after the fact, at higher cost and with less certainty than earlier detection would have required.
The goal is not perfection at any one layer. No layer catches everything, and the blind spots documented above are structural, not fixable by adding more rules to a single tool. The goal is eliminating the gaps between layers so that fraud has no unmonitored stage to exploit.
What This Series Covers
This post is the framework introduction. Each of the five subsequent posts in this series goes deep on one layer: what it catches, what it misses, what tools operate there, how to evaluate coverage at that layer, and how it connects to the layers on either side.
Series reading order:
-
Layer 0: Traffic Filtering and Network Defense — WAF rules, rate limiting, IP blocklisting, CDN-level threat filtering, and what passes through anyway.
-
Layer 1: Interaction and Session Intelligence — Behavioral signals, device fingerprinting, session analysis, CAPTCHA types, and the identity blind spot.
-
Layer 2: Input and Signal Intelligence — Email, IP, and identifier risk scoring at submission, and why this is the highest-leverage pre-onboarding layer.
-
Layer 3: Identity Verification (coming soon) — KYC, eKYC, AML, and what happens when the layers above it have gaps.
-
Layer 4: Transaction Fraud and Trust and Safety (coming soon) — Post-onboarding signals, account takeover, and why downstream tools inherit upstream quality.
You do not have to read the series in order. If you already have strong Layer 0 coverage and are evaluating your pre-onboarding gap, start with Layer 1 or Layer 2. If you are building a new stack from scratch, the reading order above follows the user lifecycle and is the most useful sequence.
Where to Start
If you are new to the Identifier Trust Layers framework, the most actionable starting point is Layer 0. Understanding your network-level coverage is the foundation for evaluating everything above it.
Layer 0: Traffic Filtering and Network Defense
Or jump directly to the layer most relevant to your current gap:
- Layer 1: Interaction and Session Intelligence — if you are evaluating behavioral and session-level coverage
- Layer 2: Input and Signal Intelligence — if fake leads, form spam, or identifier quality is your primary concern
- Layer 3: Identity Verification (coming soon) — if you are assessing your KYC workflow and upstream dependencies
- Layer 4: Transaction Fraud and Trust and Safety (coming soon) — if you are dealing with post-onboarding fraud and want to trace it upstream
If you want to see how Fraud Protection addresses the pre-onboarding trust gap at Layers 1 and 2, the product overview is a practical starting point.