Layer 2: Input and Signal Intelligence
This is Post 3 in the Identifier Trust Layers series by Opportify, a framework that maps where trust can be evaluated across the full user lifecycle, and where the gaps are. Each post covers one layer in depth.
The Identifier Trust Layers are Opportify's original framework. It is not an industry standard or third-party model.
Every form submission contains at least three distinct signals. Most teams evaluate one.
The typical pre-onboarding check is an email deliverability query: does this address resolve to a real mailbox? That check answers one narrow question. It leaves the IP address entirely unevaluated. It says nothing about whether the email domain is three days old and registered on a disposable provider. It does not consider whether the form fields were filled with coherent content or with values that individually pass format validation while collectively describing a fabricated identity. And it produces a binary pass or fail, when what you need is a risk profile.
This is the gap that Layer 2 in Opportify's Identifier Trust Layers framework is designed to close: Input and Signal Intelligence. It is the layer that activates at the moment a user submits their identifiers, where the email address, the IP address, and the content of the form itself all carry intelligence that most teams are not reading.
Every Form Submission Contains Three Signals. Most Teams Check One.
At the moment of form submission, three categories of signal become readable simultaneously.
The first is the email identifier: not just whether the address is deliverable, but what kind of address it is, what infrastructure it sits on, what the domain's history and reputation suggest, and how the full email risk profile scores across a range of fraud dimensions.

The second is the IP address: not just the approximate location, but the connection type, the threat intelligence footprint across dozens of external feeds, the ASN reputation, and whether the IP is routing through infrastructure that is characteristic of proxy networks, datacenter ranges, or known abuse patterns.
The third is the input and form content: the quality of the data submitted across all fields - whether names, company fields, message bodies, and declared attributes are consistent with genuine intent, or whether the pattern across them signals low-quality, fabricated, or automated input.
Most pre-onboarding pipelines evaluate the email and discard everything else. Some add a basic IP geolocation check. Very few evaluate all three, and fewer still evaluate them together rather than independently. The result is a layer of intelligence that exists at every form submission and goes almost entirely unused.
What makes this layer particularly important is timing. By the moment a user submits your form, Layers 0 and 1 have already applied. Network filtering has already passed the request. Behavioral monitoring has already produced a session profile. But the identifiers themselves - the email, the IP, the submitted content - have not been evaluated at all until this moment. Layer 2 is the first time in the pipeline that the actual content of the submission is under examination.
What the Email Identifier Actually Reveals
Email deliverability is the entry point, not the destination. A deliverable email address - one with a valid MX record, a reachable mailbox, and no hard bounce history - is a necessary but not sufficient condition for a low-risk submission. What sits around that deliverability check determines whether the email is actually a signal of legitimate intent or merely a functional address that happens to resolve.
Provider classification is the first dimension beyond deliverability. Email providers sort into categories that carry distinct risk profiles: free consumer providers (Gmail, Yahoo, Outlook), disposable or temporary address services, relay or forwarding services, role-based addresses (info@, admin@, noreply@), and private or organizational domains. These categories are not equally risky by default, but they are meaningfully different. A free consumer email from Gmail used for a B2B SaaS sign-up is within the normal range of behavior. The same format used for a bulk trial sign-up across hundreds of accounts is a pattern that provider classification alone does not catch - but it is context that matters when evaluating the submission alongside other signals.
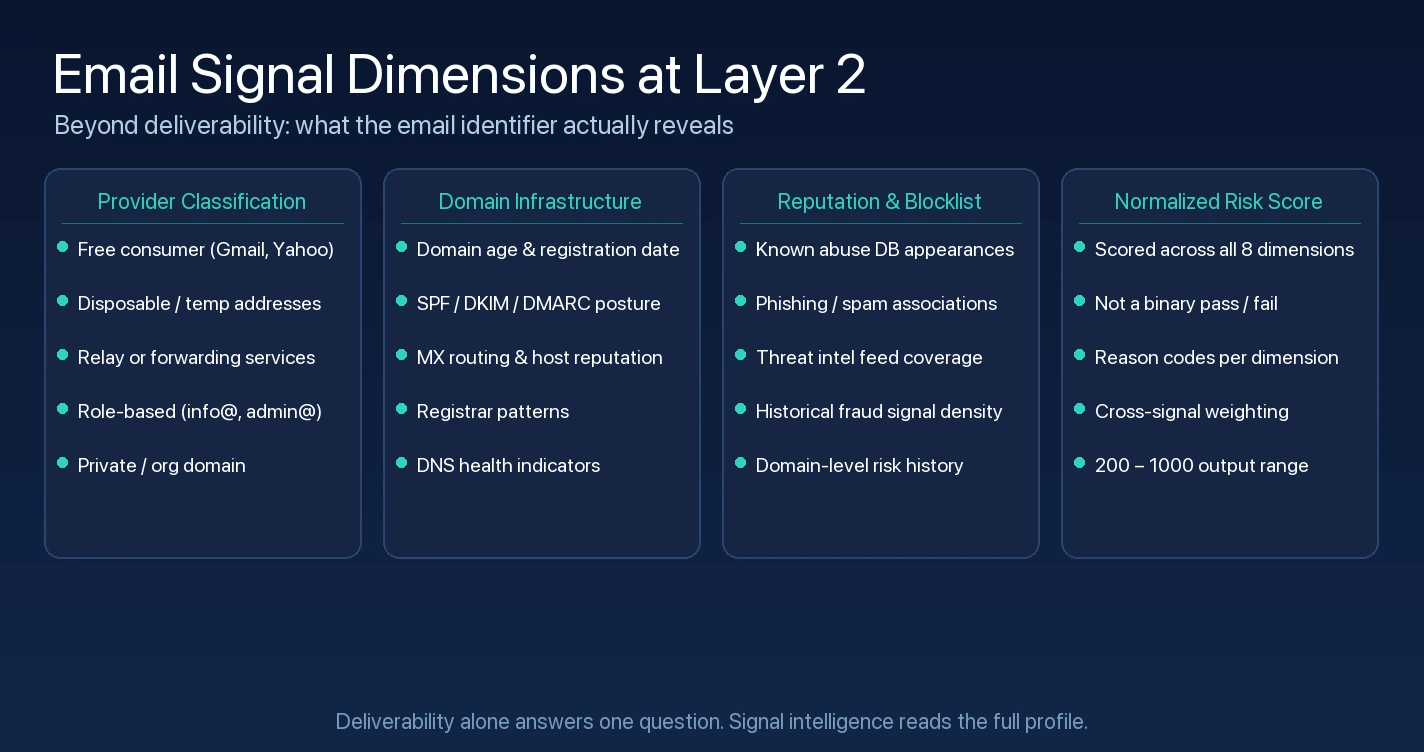
Disposable email providers are a more direct indicator. These services exist specifically to provide throwaway addresses for users who do not want to expose their real email. Their use in a sign-up flow is not evidence of fraud, but it is a signal worth weighing: a user who is actively avoiding accountability for their contact information is a different risk profile than one who provides a persistent address.
Domain infrastructure adds depth that deliverability checks entirely miss. A domain registered three days ago, with no SPF record, no DMARC policy, routing through a single MX host on a provider that specializes in cheap bulk domain registrations, is a different risk environment than a twenty-year-old organizational domain with a mature DNS posture. Domain age is not itself a fraud indicator - legitimate startups register new domains - but combined with other signals, a very young domain with minimal infrastructure is consistently over-represented in high-risk submission patterns.
Reputation and blocklist status adds the historical dimension. A domain that appears across known abuse databases, has been associated with phishing campaigns, or carries negative signals from threat intelligence sources is not the same as a clean domain regardless of deliverability. The email resolves, the mailbox exists, and the address is being used for fraud. Deliverability confirmation does not distinguish between these cases. Reputation data does.
Risk scoring across dimensions is what pulls these signals together. Rather than a binary deliverable or not deliverable result, a fully instrumented email analysis produces a normalized risk score across provider type, domain age and posture, reputation status, and additional dimensions like whether the address pattern is consistent with a real person or with a synthetic or randomly generated string. The score reflects the full picture of what the email identifier reveals - not just whether mail can be delivered to it.
The trap is the same in every case: a deliverable email from a three-day-old domain registered on a disposable provider, with no DNS authentication posture and a blocklist appearance, is not a clean record. It is a fraud signal expressed as a functional email address. Checking deliverability alone produces a pass. Evaluating the full email identifier produces the signal it actually carries.
What the IP Address Actually Reveals
The IP address that accompanies every form submission is one of the most information-dense signals available in a submission record. It is also among the most frequently underused.
Connection type is the foundational dimension. An IP address routes through some kind of infrastructure - a residential ISP, a mobile carrier, a datacenter, a known VPN or proxy service, a Tor exit node, a satellite provider, a zero-trust network access (ZTNA) gateway. Each of these connection types carries a distinct risk profile in the context of form submission fraud.

Datacenter IPs are not inherently fraudulent - developers, automated testing pipelines, and many legitimate users route through cloud infrastructure. But a datacenter IP submitting a consumer-facing sign-up form is not the same as a residential IP doing the same. The context matters. A Tor exit node IP submitting a form is a stronger signal: Tor is specifically designed to anonymize the user's origin, and the population of users who anonymize their identity during a form submission is not a representative sample of legitimate sign-ups.
VPN and proxy IPs occupy a nuanced position. Consumer VPN usage is widespread and often unrelated to fraud intent. But certain proxy networks are disproportionately associated with abuse: rotating residential proxy services used for credential stuffing, datacenter proxy pools used for bulk account creation, and specific ranges known across threat intelligence feeds for sustained abuse activity. The distinction between a user on a commercial VPN and a submission routing through an abuse-associated proxy range is a meaningful difference that connection type analysis can surface.
Threat intelligence aggregation is where IP risk analysis moves beyond connection type. A single threat intelligence source provides limited coverage. Aggregated across thirty or more feeds - blocklists, abuse databases, known threat actor infrastructure, network reputation services - an IP's footprint across the threat landscape becomes a much more reliable signal. An IP that appears on a single blocklist could be a stale listing or a false positive. An IP that appears across thirty threat intelligence sources simultaneously is carrying unambiguous signal.
Geolocation consistency adds a cross-field dimension. The IP address carries an implied geographic origin. If a form submission declares a company location in Germany and routes through an IP geolocating to Southeast Asia, the inconsistency is not itself proof of fraud, but it is a signal worth evaluating alongside others. Users on VPNs will routinely produce geolocation mismatches without fraudulent intent. But mismatches between declared location and IP origin, combined with other elevated signals, are consistently over-represented in high-risk submission patterns.
The trap: a residential IP from a well-regarded ISP passes every basic check cleanly. It is not a Tor exit node. It is not a datacenter IP. The geolocation is consistent with the declared location. And it is routing through a residential proxy network that aggregates millions of consumer IP addresses and rents them out for automated abuse at scale. Basic IP geolocation detects none of this. Threat intelligence aggregation across a sufficient number of sources surfaces it.
What Input Quality and Content Signals Actually Reveal
The third signal category is the one most fraud defenses do not evaluate at all: the quality and consistency of the content submitted across the form fields themselves.
Field content quality is the starting point. A name field containing a numeric string, a sequence of random characters, or a single letter is not producing the signal of a genuine person registering for a service. A company field containing a one-word non-entity or a generic placeholder is not consistent with a real B2B sign-up. These patterns are often individually defensible - abbreviated names exist, some companies have short names - but they are consistently over-represented in low-quality and fraudulent submissions.

Role-based inputs deserve specific attention. An email like info@domain.com or admin@domain.com submitted in a context where individual registration is expected is a different pattern than a personal address. The role-based designation suggests either that an organization is submitting collectively (normal in some contexts) or that whoever is filling the form is not personally accountable for the submission (a pattern associated with bulk operations and disposable registrations).
Input pattern anomalies surface a different dimension. When every field in a form was pasted rather than typed - no character-by-character entry, no incremental fill - it suggests either browser autofill, a script populating the fields programmatically, or a human operator working through a list. When the same field structure appears identically formatted across multiple submissions with different email addresses and different IPs, it suggests a template. When form content is suspiciously consistent in formatting - identical capitalization patterns, identical punctuation, identical spacing - across submissions that appear to be from different sources, the consistency itself is the signal.
Cross-field consistency is the dimension that produces the most diagnostically useful signals. Each submitted field carries an implied claim about the submitter. The declared company name implies an organization. The email domain implies an affiliation. The IP address implies a geographic origin. The stated location, if present, implies a physical context. When these implied claims cohere, the submission is more consistent with a real person. When they conflict - the email domain does not match the declared company, the IP geolocation contradicts the stated location, the company name is not consistent with the described business need - the inconsistency is a pattern worth examining. Each field passes its own format validation. The relationship between fields is what reveals the fabrication.
Message and inquiry content, where present in the form, carries its own signal layer. Open text fields - an inquiry message, a project description, a use-case explanation - reflect the intent and context of the submitter. Generic, templated, or semantically empty content (the classic "I am interested in your services, please contact me" message that could have been generated for any product) is a weaker trust signal than a specific, contextually relevant inquiry. This is not a binary classifier, but it is a dimension that, combined with elevated signals from email and IP analysis, contributes to the overall pattern.
The trap is precisely stated in the series outline: every field passes format validation. The pattern across fields reveals the fabrication. A form submission in which the email passes deliverability, the name has no format errors, and the company field is populated - but the email domain is unrelated to the declared company, the IP routes through a datacenter in a different region than the stated location, and the inquiry message is generic enough to apply to any business - is not producing a clean signal. It is producing the appearance of a legitimate submission while the cross-field pattern reads as fabricated.
Why Single-Signal Analysis Fails Against Sophisticated Fraud
Fraudsters know which signals are checked and optimize accordingly. This is not speculation - it is the observable consequence of how fraud operations evolve in response to the defenses they encounter.
A fraud operation that encounters email deliverability checks will stop using obviously invalid or disposable email addresses and start using free consumer email addresses or aged domains that pass basic deliverability checks. A fraud operation that encounters IP blocklists will rotate through residential proxy networks that do not appear on the threat feeds the target system is checking. A fraud operation that encounters behavioral analysis will add human operators or slow down its automation to produce more plausible session signals.
What fraud operations cannot easily do is simultaneously optimize against all three signal categories at once while maintaining the scale required to make the operation economically viable.
The datacenter-and-disposable-email combination is individually flaggable at each signal but, evaluated together, is almost certainly fraud. The population of legitimate users submitting from datacenter IPs using disposable email addresses is very small and context-dependent. In most sign-up flows, this combination describes a pattern rather than an edge case.
The clean-email-and-residential-proxy combination is the more sophisticated variant. The email passes every check. The IP is residential and appears clean to basic geolocation. What is not visible in basic analysis: the residential IP is routing through a proxy service with an elevated presence across thirty threat intelligence feeds, and the email domain was registered forty-eight hours ago on a provider that processes high volumes of fraudulent domain registrations. Neither signal alone is conclusive. Together they are.
The medium-risk-email-and-mismatched-geolocation combination is the kind of pattern that single-signal analysis consistently produces false negatives on. The email is slightly elevated in risk - a free provider with no established history - but not unusual enough to reject. The geolocation mismatch could be a VPN. Individually, neither triggers a block. Combined with input quality signals that show a generic inquiry and a company name that does not resolve to a real entity, the pattern becomes coherent.
The optimization loop that single-signal analysis creates is the core problem. When fraudsters know that one signal is evaluated and others are not, they optimize the one they know is checked and exploit the signals that are not. Multi-signal analysis closes the loop by requiring that all available signals be clean simultaneously - a requirement that is structurally harder to satisfy at scale.
The Correlation Layer: Where the Real Patterns Live
Individual signals carry risk assessments. Combined signals carry pattern recognition.
A low-risk email, a clean residential IP, and coherent form content describe a submission with the profile of a real, low-intent risk user. The combination is more valuable than any single signal because all three independent signals point in the same direction.

A medium-risk email, a VPN IP, and a form completed in two seconds with pasted content describe a very different pattern - one that is consistent with automated or semi-automated identity fabrication regardless of whether any individual signal would trigger a block on its own. The combination is informative even when the components are individually ambiguous.
A disposable email, a datacenter IP, and a form submitted instantly with generic content describe an automated submission pattern in terms that are unambiguous when all three signals are present simultaneously.
The value of correlation is not just in the high-risk end of the distribution. It is in the large middle band of submissions where individual signals are elevated but not conclusive. Most fraud does not arrive with a Tor exit node IP, a known-bad email domain, and a clearly scripted form fill. It arrives with signals that are each individually explainable as edge cases of legitimate behavior. Correlation is what transforms a collection of ambiguous signals into a pattern with meaningful predictive value.
This is also why fragmented signal checking - running email through one vendor, IP through another, and combining the outputs manually - produces materially worse signal quality than integrated analysis. Correlation requires that signals be evaluated together, with each signal's output informing the weight assigned to others. An elevated IP risk score changes how a borderline email risk score should be interpreted. A coherent input quality profile reduces the apparent risk of an IP that is elevated but not conclusive. Signal interaction is where the accuracy is.
How Opportify Combines All Signals Into a Single Analysis
Email Insights and IP Insights are each available as standalone APIs, designed for teams that need email or IP risk analysis in isolation. But the most significant signal value at Layer 2 comes from their combined evaluation.
In Fraud Protection, email and IP analysis are executed together on every form submission, alongside behavioral signals captured at Layer 1 and input quality signals from across the submitted form fields. No manual correlation step. No separate vendor calls. No fragmented outputs that a team has to interpret independently.
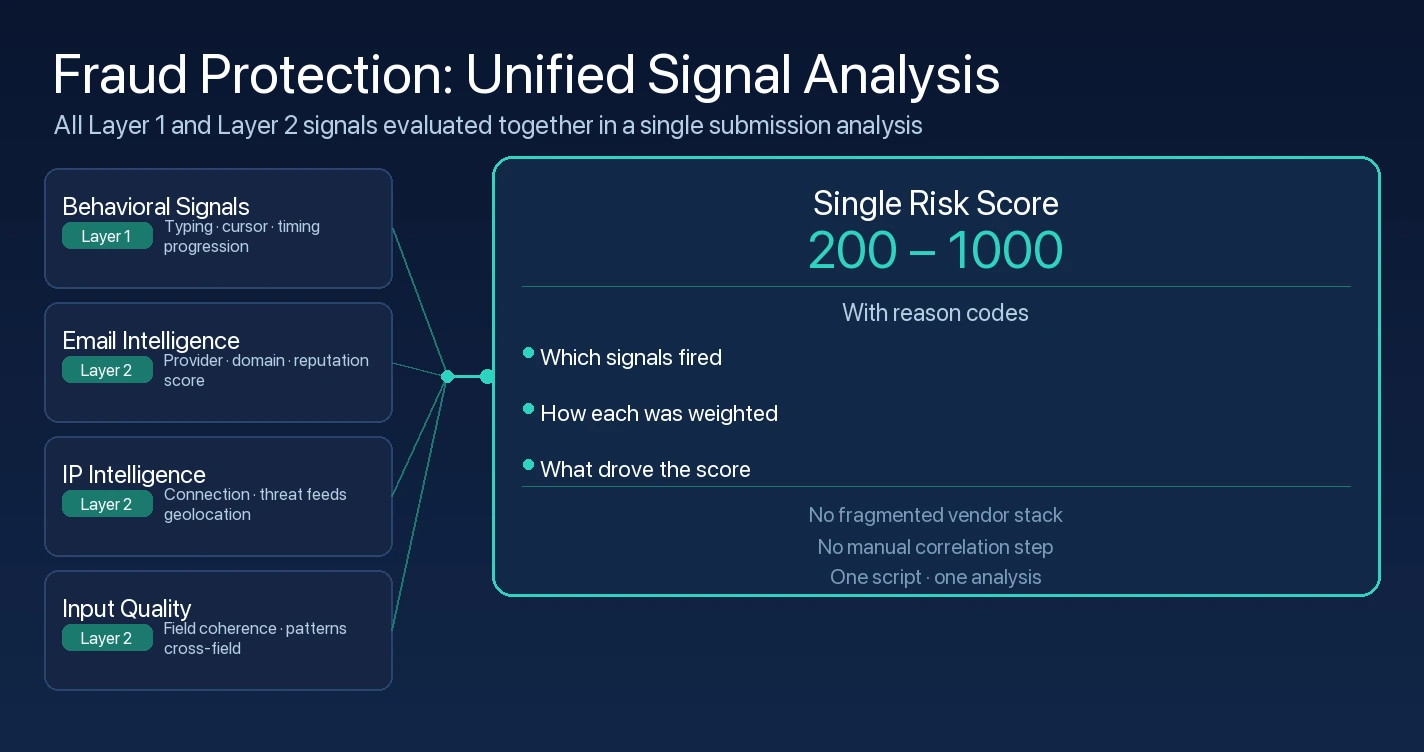
The output is a single risk score on a 200-1000 scale, with reason codes that identify which signals contributed and how. A score of 850 on a submission from a datacenter IP, a three-day-old disposable domain, and a generic inquiry message is not just a number - it is a specific pattern of signals that the reason codes describe. Your team sees what fired, why the score landed where it did, and which combination of signals drove the result.
The risk score is advisory. Your team controls the thresholds and the actions. A high-risk submission can be flagged for manual review, routed to additional verification, surfaced in your CRM with a risk annotation, or blocked before it reaches your pipeline - depending on how your workflow is configured. Fraud Protection provides the signal. The downstream decision remains with your team.
One script, added once to your form page, provides the full Layer 1 session monitoring and Layer 2 signal analysis simultaneously. Email, IP, behavioral, and input quality signals are all captured and evaluated in a single submission analysis. The session monitoring that surfaces how the form was filled operates at the same layer as the identifier analysis that evaluates what was submitted.
For teams currently running a single-signal approach - an email deliverability check, a basic IP geolocation lookup, or CAPTCHA alone - Layer 2 is the layer where the signal that is currently available on every submission but not being read first becomes visible. Every form submission your current stack evaluates already contains the email, the IP, and the form content. The question is whether you are reading what those signals actually say.
Start your free Fraud Protection trial (no credit card required)
Key Takeaways
- Every form submission contains three distinct signals. Email, IP, and input quality are all readable at the moment of submission. Most fraud defenses evaluate one.
- Email deliverability is the starting point, not the signal. What matters is the full profile: provider type, domain age and infrastructure, reputation, blocklist status, and normalized risk score across all dimensions.
- IP connection type and threat intelligence are different evaluations. A residential IP that is not a Tor exit node is still high risk if it appears across thirty threat intelligence feeds. Connection type tells you the network path; threat intelligence tells you the history.
- Input quality and cross-field consistency are the most underused signals at this layer. Every field passes format validation. The pattern across fields - whether they cohere into a plausible identity - is the signal that reveals fabrication.
- Single-signal analysis creates an optimization loop. Fraudsters optimize the one signal they know is checked. Multi-signal analysis requires that all available signals be clean simultaneously, which is structurally harder to achieve at scale.
- Correlation is where the accuracy lives. Individual elevated signals are often ambiguous. The combination of an elevated email, a high-risk IP, and anomalous input quality is a pattern that is coherent even when no individual signal is conclusive.
- Layer 2 has its own boundary. Signal intelligence evaluates the quality of the identifiers and the submission content. It does not verify whether the identity behind them is who it claims to be. That is Layer 3: Identity Verification.
Continue to Layer 3: Identity Verification (coming soon).
Part of the Identifier Trust Layers series by Opportify. Previous: Layer 1: CAPTCHA Passed the Session. Here Is What It Did Not Catch.. Related reading: Email Risk Score Explained, Email Spoofing Explained.